Now, deep learning is a subset of machine learning. The learning process in machine learning is similar to the one in deep learning.
Step 1
First we import the data. We apply the necessary changes/augmentations to it. We also divide the data set into 2/3 parts, training, validation, test. The training data set is the data set that our model will fit to. The validation set is used during training to see how well the model performs. As it is not part of the training set, we can see if the model overfits or not. The test set is used to compare different models.
Step 2
Defining the model. Our model is what makes predictions on our input data. In deep learning, there are many architectures that we can use, there are some that are predefined for us like ResNets, or we can make a custom one! Predefined architectures can come with deep learning libraries like pytorch, which makes it easy for us to create one in a line of code or two.
Step 3
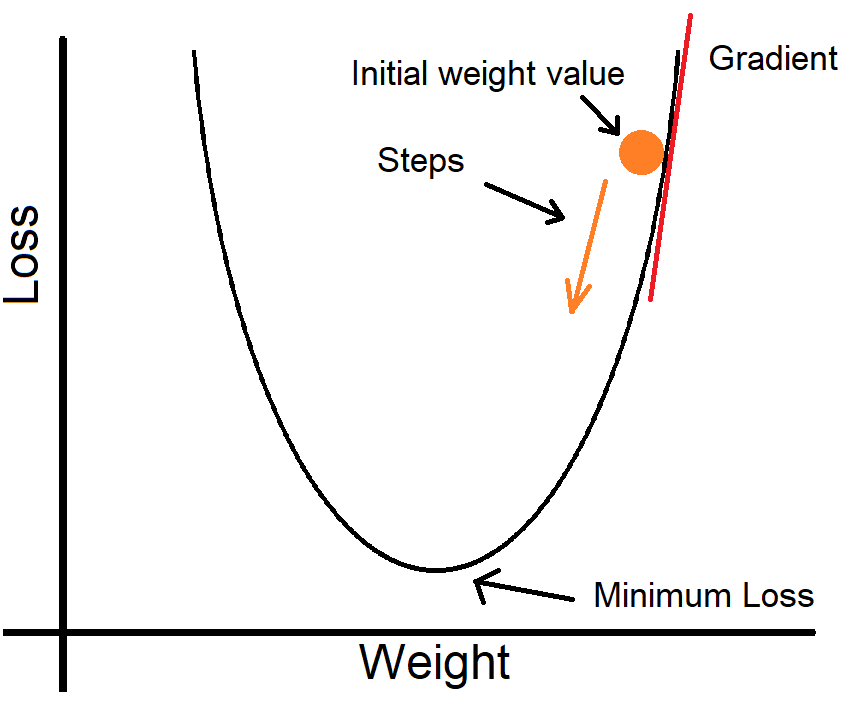
Now for the fun part: fitting! Fitting is the process of changing the models parameters so that it can make more accurate predictions on the input data. We use the training data to fit our model. An epoch is a term that is used to refer to one pass through the training data. We decide this number before training. We also set a learning rate, which is by how much do we want to change. If the learning rate is too big, we might keep jumping over the minimum and never reach it, while if the learning rate is very small, it'll take a long time to train. We change it in the direction that allows the loss to be minimized. Here the gradient is positive, so we are going in the other direction so that we can decrease the loss. Our goal is to reach the smallest loss we can. Not all graphs look like the one below. Some have many local minima. This can mean that we get stuck in one of them and not reach the global minima.
Overfitting
Overfitting happens when your model is biased towards its training data and isn't general enough. This model is therefore useless as it won't do good in the real world which is what we're aiming for. If a model performs very well on the training data but poorly on the test data, this probably means it's overfit. There are many ways to prevent overfitting, like data augmentation and early stopping which we'll hopefully cover in this course.
Conclusion
So that's it for lesson 2! We now have a general idea of how machine learning works. We can now start learning the implementation! See you next lesson!